My Thoughts on Enrollment Science
TLDR;
Enrollment Science is my attempt to relate the emerging role of Data Scientists to Enrollment Management Divisions within Higher Education. Let’s get real. Higher Ed is BIG business, and it’s about time that we start to embrace advanced techniques (i.e. the methods industry has been using for many years now) in order to be more efficient. We need to think differently about how we run our organizations, and in my opinion, it starts with the principles of Enrollment Science.
Intro
Over the last few weeks, I have begun tagging posts on Twitter with the
hashtag #emsci. It’s about time that I discuss what I believe to
be Enrollment Science. As far as I can tell, this
post introduced
the notion that:
Data is the new oil
That was back in 2006. In 2012, this Forbes articleseemingly struck a chord. The concept of “Data Science” has been gaining tracking ever since.
What is #emsci all about?
At the end of the day, there is both an art and a science when it comes to Enrollment Management, the term coined by Jack Maguire. As an industry, not only do we collect an immense amount of data internally, but we report extremely detailed information to a wide range of external audiences. Outside of public companies listed on stock exchanges, no other industry is required to publicly expose this level of data. It’s about time that we begin to use these datasets more effectively. I am calling this Enrollment Science, a play off the wildly over-used term, Data Science.
Enrollment Science
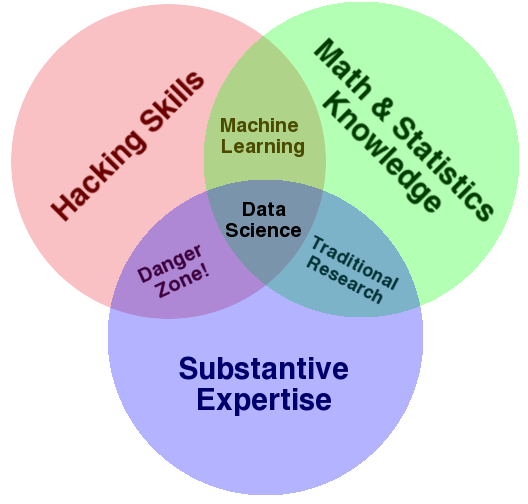
Drew
Conway famously
used the venn diagram below to describe the skills required of today’s
data scientist.
Aside from communications, #DataAnalysis most critical skill for senior level #admissionjobs @NACAC http://t.co/lxhYE8B8PJ #emchat #edchat — NACAC (@NACAC) July 30, 2014
To be fair, the application of analytical techniques to solve business problems within higher ed is not new, and a number of vendors have been providing these services for some time now. However, we rarely have “Big Data” in Enrollment Management, but I will talk about that in future posts. Most of us who analyze Enrollment Management problems barely have Medium Data. However, what we do have is disparate data.
Enrollment Science
In this post, I want to discuss the relationship between Data Science and Enrollment Management. I contend that Enrollment Scientists:
- Have both educational and practical experiences dealing with scientific method
- Are capable with one or more programming languages that are executed on the command line. I will come back to this in a moment. If you prefer Linux environments to Windows, you are well on your way to being an Enrollment Scientist. The key takeaway is that dirty data does not scare you, and you rarely believe that “manual” data cleaning is the correct approach. If your data operations staff are cleaning things manually, there is a good chance your process can be improved.
- When it comes to discussing advanced methodologies and the results from these approaches, Enrollment Scientists are able to synthesize the key facts to a non-technical audience. I believe this skill to be the hardest of them all.
To put it simply, I believe that Enrollment Scientists are capable of understanding the strategic reasoning behind a problem, can hack together datasets that come in a variety of shapes and sizes, and are able to effectively communicate the “so what” behind the results to senior leadership. Basically, Enrollment Scientists are the intersection of IT, Analytics, and Management.
Technical Tools of the Trade
As referenced above, predictive techniques are just one tool in the Enrollment Scientist’s toolbox. The items below are the skills that I believe are critical to the success of an Enrollment Scientist.
- Basic understanding of the command line (free): Often times the robust open-source tools require execution of a few basic commands in a terminal. Trust me, it’s not that scary. Do you point and click your way to do the same task all of the time? More than likely, you can write some basic code to automate that boring task! All operating systems provide users access to the command line.
- R and Python (free): Currently there is a pretty heated debate on “Python versus R”, but I believe that successful analysts today need to have facility with both languages. Each have their strengths. I am significantly better in R, but can usually hack something together in Python if need be. Admittedly there are times when R begins to choke, but I rarely have to write rock solid production code; simply, I just need a reproducible answer . Worth noting, both R and python are being rapidly developed and are used at all of the major tech companies today, including Facebook, Google, Twitter, and Spotify, just to name a few. Did I mention that both are free? Yes, free…. SAS and SPSS are expensive and irrelevant, and you can quote me on that……
- Tableau (relatively speaking, cheap as hell): In 2014, Gartner ranked Tableau as the leader in BI software. The BI tool is an amazing resource for exploring data. While it is not intended to clean data, you can often getaway with some lightweight data manipulation. Tableau’s real strength is allowing you to rapidly explore your cleaned datasets. I often use Tableau to look at the data that I push to MySQL after collecting/cleaning in R.
- **SQL (free): **Enrollment Scientists will inevitably be asked to extract a variety of datasets from Relational Databases (think: your SIS, or Banner). Knowing some basic SQL can really cut down on the turnaround time to answer key strategic questions.
- **Relational Database Engines (free): **Today’s Enrollment Scientists need to have a basic understanding of the variety of ways to store data within databases. I have MySQL installed on all of my machines; it’s simple and just works. Both R and Python provide interfaces to MySQL, as well as a included connection to SQLite. We can always store data in text files, but sometimes it becomes easier to hack together a pipeline where you store your cleaned data into a RDBMS. Tableau, listed above, has an amazing array of drivers to access the datasets that you build in your RDBMS of choice. Both MySQL and SQLite are free.
- NoSQL Databases (free): Contemporary datasets are not rectangular in nature. If you play around with Twitter’s API, you will notice that the data feed is returned in JSON format. In R, you can map JSON to a list of lists, and in python, to a dict. The point being that getting raw data in a row by column format is a luxury. My two favorite tools at the moment are MongoDB, which nicely stores JSON, and Neo4J, which effectively handles graph data. Both MongoDB and Neo4j have bindings to R and Python, so we can work with the raw data just like we would in SQL. Both MongoDB and Neo4j are free.
- Machine Learning Techniques (free): Machine learning means a wide array of things these days, but to me, it’s having a good understanding which advanced technique can (and should) be applied to your current research problem. This means having a firm understanding of when to use regression, clustering, and data reduction techniques. It’s also worth noting that some of the “hotter” techniques like sentiment analysis, graph analysis, and recommendation engines have a number of applications in Enrollment Management. In future posts, I will discuss how to use these techniques. In the short run, here is a previous post where I use a very simple toy dataset to highlight how you can leverage data to predict student yield.
- Markdown (free): Markdown is a markup language that is not only easy to read and write, but can be converted to a number of output formats, including HTML and Word. In R, it’s possible to automate your entire workflow using Markdown. You can clean data, generate slide decks, journal articles, and even interactive websites when you use RMarkdown. So what? Your productivity skyrockets when you can build an HTML report and have it emailed to you every morning before you get into work. Trust me, it’s amazing.
- Github (free-ish): Github is a cloud-based solution to store your Git (version control) projects online. Git makes it possible for your to lock in versions of your code and analysis, even reports. No more saving your files with v1, v2, etc. It’s the bee’s knees but does take some getting used to. The learning curve is worth the effort.
What’s Next?
Outside of Tableau, all of the skills and software listed above are free, as in, free beer. Even Tableau has Tableau Public, but there are usage limitations, Nonetheless, everything you need to be effective within Enrollment Science is (basically) free. Of course, it takes time to hone these skills, many of which can not be learned from a text book, but the efforts will pay off in spades. Enrollment Science is no longer a luxury, but a necessity in order to compete in today’s rapidly changing higher education landscape. From here, I aim to highlight how easy it is to get started within Enrollment Science. I am very passionate about this topic, so I hope to share that passion with you. My aim is to introduce you to the tools listed above, and apply advanced techniques to datasets that you already have in-house. Today, Enrollment Management divisions are asking increasingly complex questions. Luckily, industry (i.e. for profit companies) have proven that we can leverage data to improve our position in the market, so it’s about time we get better at data within Enrollment Management.